des représentations floues
(version abrégée)
Maurice Clerc 1995
Il en découle mathématiquement des estimations de ressemblances, symétriques, et admettant une transitivité partielle. Dans la mesure où, en particulier, les mémoriels fondés sur ces principes doivent être admis par les utilisateurs comme des extensions de leur mémoire propre, il est important de vérifier que ces propriétés sont psychologiquement acceptables.
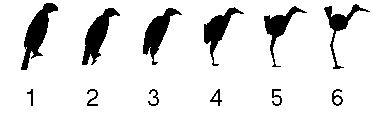
Dans cet article, il s'agit surtout de présenter la démarche, et quelques outils mathématiques. Comme fil conducteur nous avons choisi un exemple simple de classement de ressemblances de couples d'objets (des silhouettes d'oiseaux) par des sujets humains.
- d'une part chaque silhouette intermédiaire est calculée en fonction des deux extrêmes par variation linéaire d'un seul paramètre numérique
- d'autre part cette simplicité n'est pas évidente visuellement,surtout si l'on n'a jamais sous les yeux la séquence entière dansl'ordre (cf. figure 1)
Figure 1 Les silhouettes de base. Chaque point du contour de la première silhouette a son homologue sur le contour de la dernière. Pour les silhouettes intermédiaires, le point homologue est calculé par interpolation linéaire..
Cependant des tests préliminaires ayant montré que les couples identiques étaient toujours repérés sans ambigüité, ils n'ont finalement pas été inclus dans le matériel mis à disposition des sujets, qui comprend donc 30 couples sur des fiches 3x3 cm ("vignettes").
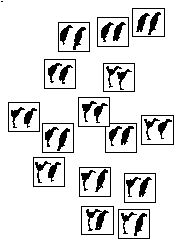
Sans entrer ici dans le détail de la population testée et du protocole, disons simplement qu'à chaque session la consigne donnée au sujet est de placer les couples de silhouettes plus ou moins"haut" sur la feuille selon leur ressemblance. La figure 2 donne un exemple de feuille de test jugée satisfaisante par un des sujets.
Chaque sujet réalise cinq sessions, à quelques jours d'intervalle, avec
cinq jeux différents de 15 couples  ,afin
d'éliminer certains artefacts (par ex. dans quelques cas, les couples sont
présentés et manipulés têtes en bas).
,afin
d'éliminer certains artefacts (par ex. dans quelques cas, les couples sont
présentés et manipulés têtes en bas).
Figure 2 Feuille de test remplie (échelle 1/3). Le sujet a eu comme consigne de placer les couples de silhouettes d'autant plus vers le haut de la feuille qu'il les trouve ressemblants, et d'autant plus bas, qu'il les trouve dissemblables.
 ?
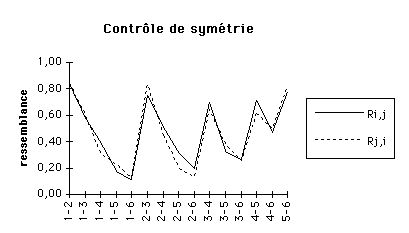
La représentation graphique (cf. figure 3) montre une assez bonne
concordance. Tous calculs faits, la probabilité de justesse de l'hypothèse
de symétrie est 0,905, ce qui, tout en étant acceptable, incite aussi à des
tests plus complets.
?
La représentation graphique (cf. figure 3) montre une assez bonne
concordance. Tous calculs faits, la probabilité de justesse de l'hypothèse
de symétrie est 0,905, ce qui, tout en étant acceptable, incite aussi à des
tests plus complets.
Figure 3 Contrôle de symétrie . Comme chaque couple aété placé plusieurs fois par les sujets, soit avec la vignette (i,j), soit avec la vignette (j,i), on peut calculer des moyennes séparées pour chaque sens. Les plus grands écarts relatifs ont lieu avec les couples " intermédiaires " pour lesquels les sujets ont plus de mal à se décider. Globalement, la correspondance est cependant correcte.
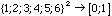 symétrique,
dont les estimations de valeurs sont issues d'une part des mesures, et
d'autre part de la contrainte que l'identité est valuée par 1. Ces valeurs
peuvent être retrouvées par une fonction de ressemblance, au sens
mathématique, appliquée à des représentations floues des objets considérés.
La figure 4 donne une telle représentation, à deuxdescripteurs.
symétrique,
dont les estimations de valeurs sont issues d'une part des mesures, et
d'autre part de la contrainte que l'identité est valuée par 1. Ces valeurs
peuvent être retrouvées par une fonction de ressemblance, au sens
mathématique, appliquée à des représentations floues des objets considérés.
La figure 4 donne une telle représentation, à deuxdescripteurs.
Figure 4 Représentations floues à deux descripteurs. Ici la somme des valeurs vaut 1 pour chaque objet, mais ce n'est pas le cas général.
Différents types de calcul de ressemblance ont été testés.( type « ensembliste », « distance », « angulaire ). Le modèle angulaire est le seul à prendre en compte la typicalité, au sens où, par exemple, les silhouettes 5 et 6 sont considérées comme plus ressemblantes que 3 et 4.
Plus précisément une formule comme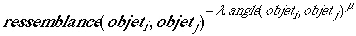 donne
(avec lambda=1,29 et mu=1,04) une excellente corrélation de rangs (0,96),
et une bonne adéquation numérique (écart relatif maximum de 0,17).
donne
(avec lambda=1,29 et mu=1,04) une excellente corrélation de rangs (0,96),
et une bonne adéquation numérique (écart relatif maximum de 0,17).
« Si la ressemblance entre i et j est grande, et si celle entre j et k l'est aussi, alors il doit y avoir une certaine ressemblance entre i et k ».,
et formulable à l'aide d'une t-norme stricte archimédienne T,par 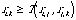 , en notant ri,j la ressemblance entre
l'objet i et l'objet j. Plus précisément, on doit avoir
, en notant ri,j la ressemblance entre
l'objet i et l'objet j. Plus précisément, on doit avoir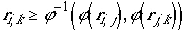
avec, pour l'automorphisme f
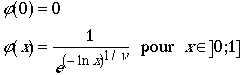
Cette forme peut paraître compliquées, mais n'est qu'une généralisation
du cas très simple 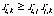 ,que l'on obtient pour
nu=1.
,que l'on obtient pour
nu=1.
La vérification exhaustive est un peu fastidieuse, mais on trouve que les
observations possèdent bien une structure sous-jacente qui contraint les
ressemblances deux à deux dans tout triplet d'objets. Ceci peut être
visualisé par une surface  ,correspondant à
nu=1,374, telle que, pour tout triplet
,correspondant à
nu=1,374, telle que, pour tout triplet 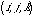 le
point
le
point 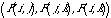 soit « au-dessus » de cette surface
(cf. figure 5). Incidemment, on peut remarquer que cette espèce de
transitivité était complétement ignorée des sujets, voir contestée après
coup par certains d'entre eux, alors même que leurs propres classements de
ressemblances s'y conformaient.
soit « au-dessus » de cette surface
(cf. figure 5). Incidemment, on peut remarquer que cette espèce de
transitivité était complétement ignorée des sujets, voir contestée après
coup par certains d'entre eux, alors même que leurs propres classements de
ressemblances s'y conformaient.
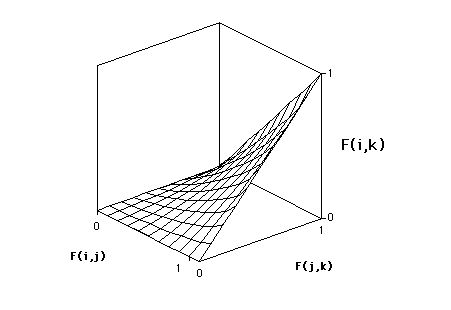
Figure 5 Surface de contrainte pour la quasi-transitivité. Pour tout triplet d'objets (silhouettes d'oiseaux), les trois ressemblances deux à deux, dans n'importe quel ordre, peuvent être considérées comme les coordonnées d'un point. Avec les données recueillies, tous les points sont « au-dessus » de la surface de contrainte.
[1] X. Chanet, Décompositions floues, ressemblances,catégorisations, 1992, France Télécom: Annecy, France.
[2] M. Clerc, F. Guérin, et al. Représentations flouesdans un mémoriel. in JIOSC (Journées Internationales d'Orsay sur les Sciences Cognitives). 1994. Orsay, France: CNRS.
[3] W. Duch, G.H.F. Diercksen, Feature Space Mapping as a Universal adaptive System, Computer Physics Communications (1994)
[4] K. Tanabe, J. Ohya, et al., Similarity retrieval method using multi-dimensional psychological space, Systems and Computers in Japan 24 (1993)98-109.
[5] A. Tversky, I. Gati, Similarity, separability, and the triangle inequality, Psychological Review 89 (1982) 123-154.
[6] A. Tversky, D.H. Krantz, The dimensional representation and the metric structure of similarity data, Journal of Mathematical Psychology 7 (1970)572-596.
[7] W. Wagner, A fuzzy model of concept representation in memory, Fuzzy Sets & Systems 6 (1981) 11-26.